AHT:让 OpenClaw 像研究者一样调参
背景:AI 正在逐步接管研究流程
一个典型的深度学习研究周期大致包含以下环节:
xxxxxxxxxx论文阅读 → 头脑风暴 → 编码实现 → 调试 → 超参数调优 → 基准测试 → 论文撰写
过去两年,这条流水线正在被 AI 工具一段一段地改写。
代码的编写与调试率先被接管。Codex、Claude Code 等 coding agent 的出现,使得研究者可以用自然语言描述需求,由 agent 完成代码编写、bug 定位和修复。对于大多数标准化的工程任务,人类的角色已经从"写代码的人"变成了"审代码的人"。
头脑风暴与论文撰写紧随其后。ai-research-skill、awesome-ai-writing 等工具开始帮助研究者梳理文献脉络、生成研究假设、起草论文初稿。虽然核心创意仍需人类把关,但 AI 已经大幅降低了从想法到文字的摩擦。
然而,超参数调优和基准测试这两个环节,至今仍然是研究回路中最耗时、最消磨耐心的瓶颈。
一个典型的调参场景是这样的:研究者启动一次训练,等待数小时甚至数天,检查 TensorBoard 上的曲线,凭直觉决定下一组参数,再启动下一次训练——如此往复。这个过程充满了上下文切换和被动等待,却又不可跳过:超参数的选择直接决定模型的最终性能,差一个数量级的学习率就可能是 SOTA 和垃圾之间的距离。
传统的自动化方法——网格搜索、随机搜索、贝叶斯优化器等——虽然不需要人盯着,但它们把超参数空间当作纯粹的黑盒:采样、评估、再采样,全程不看一行代码,也不理解为什么某个学习率比另一个好。它们只知道"什么数字产生了什么结果",却不知道"为什么"。
而真正的研究者调参时不是这样的。他们会先读模型代码,理解架构的特点;会看 loss 曲线的形状,判断是发散、停滞还是过拟合;会根据经验推理"这个 warmup 步数太短了"或者"dropout 应该再高一点"。这种基于理解的调参远比盲目搜索高效——但它要求一个人类专家持续在线,而人类专家的时间是最贵的资源。
AHT 要做的,就是补上这最后一块拼图。
AHT 是什么
AHT(Automatic Hyperparameter Tuning)是一个 OpenClaw 技能(skill),它教会 coding agent 像经验丰富的研究员一样调整超参数——先读懂项目,再推理该改什么——同时继承自动化方法"不用人盯、整夜运行"的优势。具体而言,AHT 让 agent 执行一个完整的闭环流程:
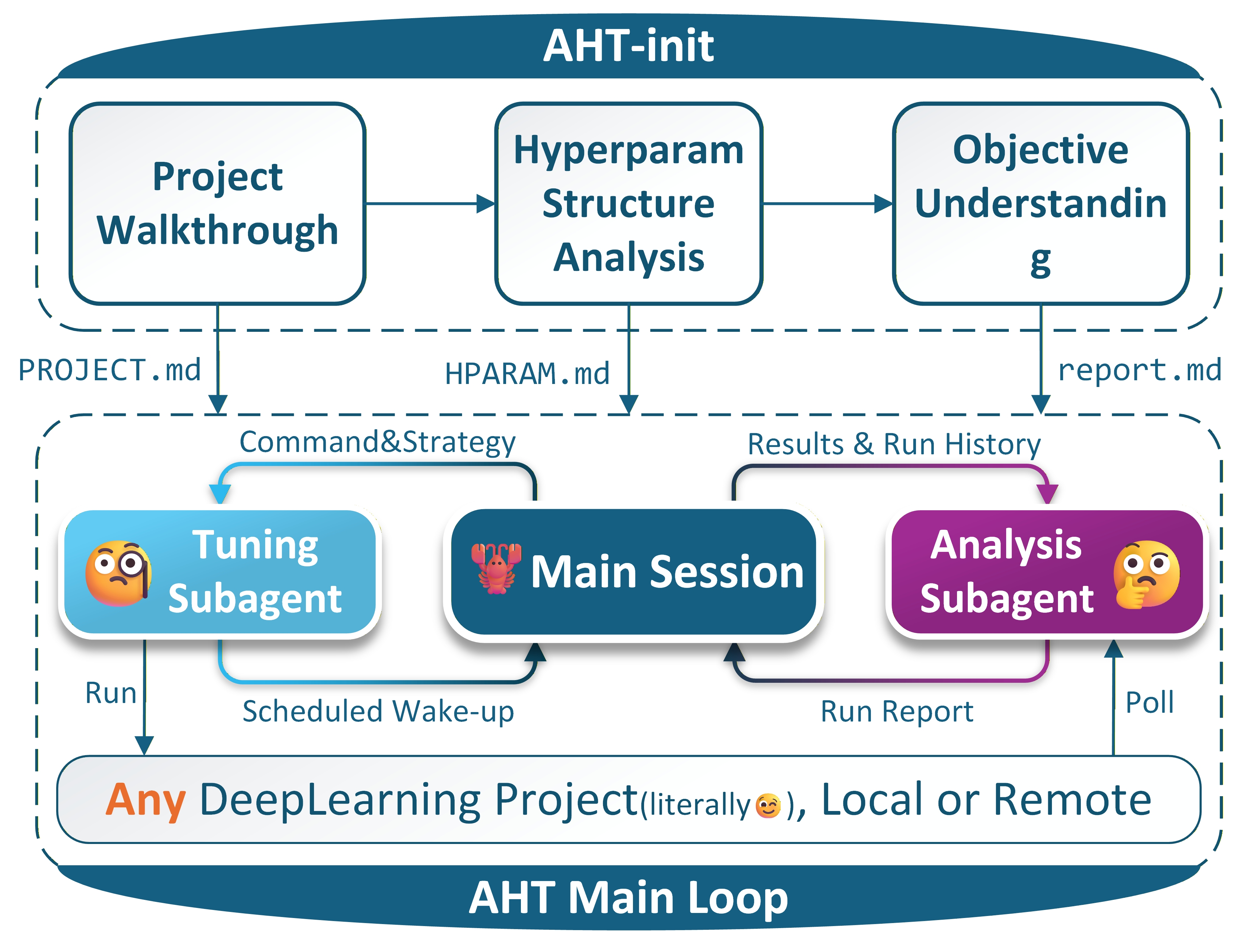
阅读项目,建立理解
Agent 遍历目标项目的代码库,解析 Hydra 配置层级,生成三份结构化文档:
PROJECT.md:项目总览——入口脚本在哪、模型架构是什么、训练流程怎么走HPARAM.md:超参数地图——Hydra 配置文件的层级关系、每个可调参数的含义和默认值report.md:任务分析——用户给出的待调试命令到底对应什么任务,哪些参数与这次实验有关
这一步相当于让 agent "读完了论文的方法部分",建立起对项目的全局认知。
制定调参策略
在跑任何实验之前,agent 先制定一份调参策略(strategy.md):优先动哪些超参、取值范围多大合理、过程中重点关注什么信号。策略会在 baseline 实验完成后根据实际观测进一步细化。
迭代调参:运行 → 分析 → 学习 → 再运行
这是 AHT 的核心循环:
运行:训练命令以异步方式在 tmux session 中后台启动(本地或 SSH 远程均可)。Agent 自己轮询进度、估算剩余时间,到点了用 cron 把自己叫醒——不需要人盯。
分析:每次训练结束后,AHT 解析 TensorBoard event 文件,提取 30 余项统计指标(初始值、最终值、最佳值、改善幅度、振荡程度、趋势拐点等)。Agent 会判断训练曲线是否出现了发散、停滞或过拟合,根据调试历史将实验分析追加到
report.md中。学习:后续每一轮决策都能看到完整的实验历史——之前用了什么 override、指标怎么变的、agent 自己怎么分析的。这个闭环让策略越调越准,而不是在参数空间里盲目搜索。
输出最终报告
所有迭代结束后,AHT 生成一份完整的调参报告,包括每次实验的配置、指标变化、分析结论,以及最终推荐的最佳超参数组合。
子智能体架构
AHT 在调参决策和结果分析两个关键环节使用独立的 subagent。每个 subagent 被注入完整的上下文(项目文档、实验历史、当前策略),独立完成决策后将结果返回给主 agent。这种架构既保证了每次决策有充分的上下文,又避免了主 agent 的上下文窗口被过多细节淹没。用户还可以通过环境变量 AHT_TUNING_MODEL 和 AHT_ANALYZE_MODEL 为两类 subagent 指定不同的模型。
与传统方法和同类项目的区别
AHT 与现有超参调试方法的核心差异在于:它不把超参数空间当黑盒,而是让 agent 像人一样先理解项目再做决策。
| 维度 | 网格/随机搜索 | 贝叶斯优化 | AHT |
|---|---|---|---|
| 是否理解项目代码 | 否 | 否 | 是 |
| 是否分析训练曲线 | 否 | 仅看最终指标 | 是,分析完整曲线形态 |
| 决策依据 | 预设网格/随机采样 | 代理模型的后验分布 | 代码理解 + 曲线分析 + 实验历史 |
| 对现有项目的侵入性 | 需要定义搜索空间 | 需要集成 Optuna API | 低——只需 Hydra 配置,不改代码 |
与其他 autoresearch 类项目相比,AHT 的定位也很明确:技能形态、Hydra 原生、低侵入、专注调参。它不试图接管整个研究流程(从 idea 到论文),而是精准解决调参这一个痛点,并以 OpenClaw skill 的形式无缝嵌入研究者现有的工作流。
技术实现
以 Skill 形态运行
AHT 由两个协作的 OpenClaw skill 组成:
aht-init:初始化技能,负责收集项目路径、运行环境、训练命令和优化目标,并与用户确认。auto-hparam-tuning:主技能,定义了从项目理解到最终报告的完整调参流水线。
基于 Hydra 配置系统
AHT 原生支持 Hydra 的配置层级和 override 机制。每次调参迭代产生的超参数变更以 override.yaml 的形式写入,不需要修改项目的任何源代码,侵入性极低。Hydra 的声明式配置恰好为 agent 提供了一个清晰的、可读的超参数接口。
异步执行与自动唤醒
训练任务在 detached tmux session 中启动(支持本地和 SSH 远程),agent 通过轮询检查运行状态。如果训练尚未结束,agent 会估算剩余时间并设置 cron 定时任务唤醒自己,而不是阻塞等待。这意味着 agent 可以同时管理多个实验,充分利用计算资源。
结构化的实验记录
每个调参 session 在项目目录下创建独立的记录结构:
xxxxxxxxxx{project_root}/aht/{日期}/{时间}/├── meta.yaml # session 元信息├── results.csv # 所有 run 的结果表├── report.md # 累积分析报告├── strategy.md # 调参策略└── runs/├── 0/ # baseline run│ ├── override.yaml│ ├── command.sh│ ├── metrics.json│ └── ...├── 1/ # 第一轮调参├── ...└── N/ # 第 N 轮
所有实验的配置、日志、指标和分析都有完整记录,支持生成 Markdown 和 HTML 格式的对比报告。
部署实例
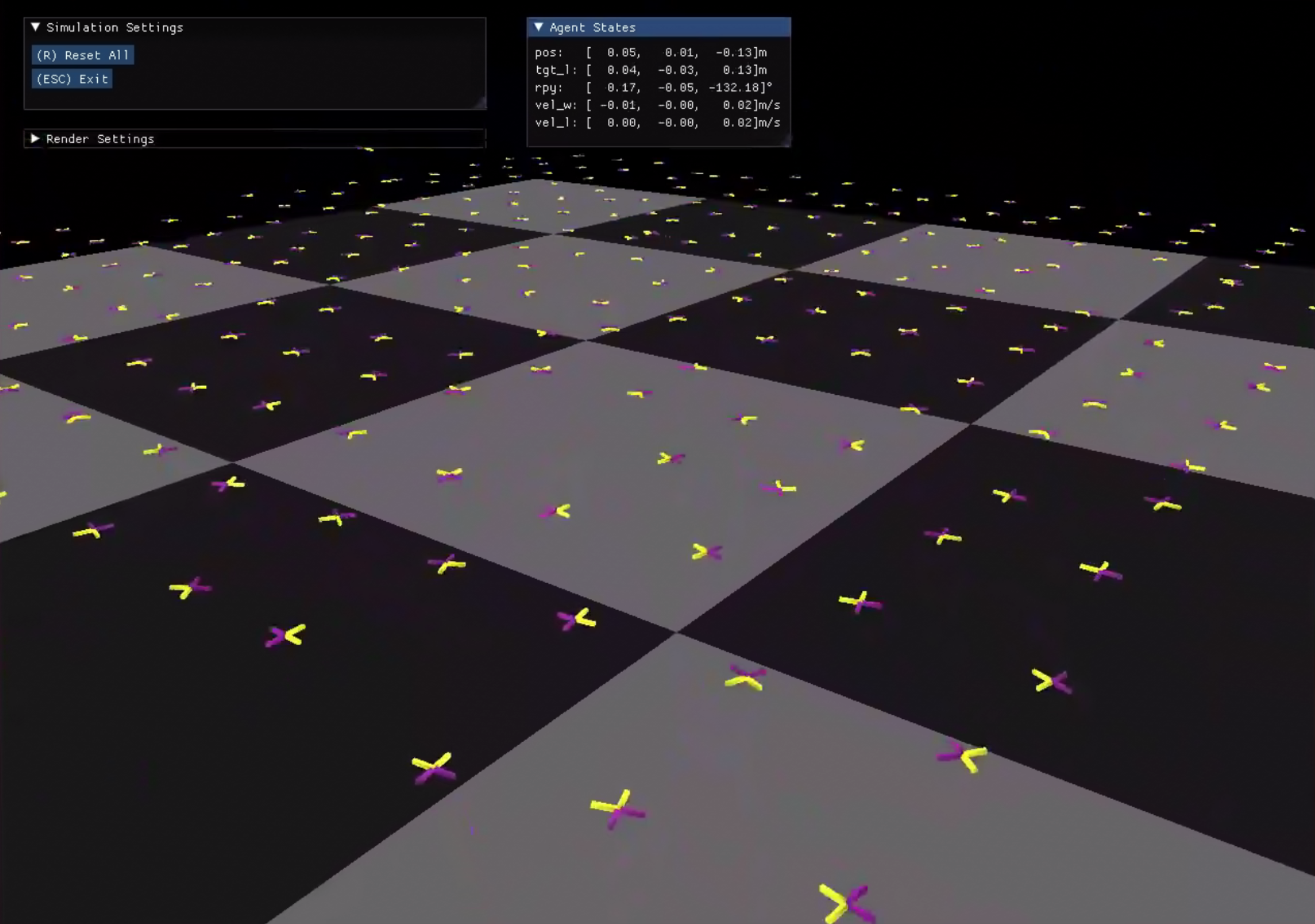
本节展示一个真实调试案例:我们在仿真器中将无人机悬停控制建模成强化学习任务,交由 AHT 进行调优。下图中,横轴是同一个 session 中各次 run 的编号,纵轴是训练结束时的任务成功率。可以看到,agent 在前几轮快速探索后逐步收敛到更优的超参数组合,成功率呈现出明显的上升趋势。
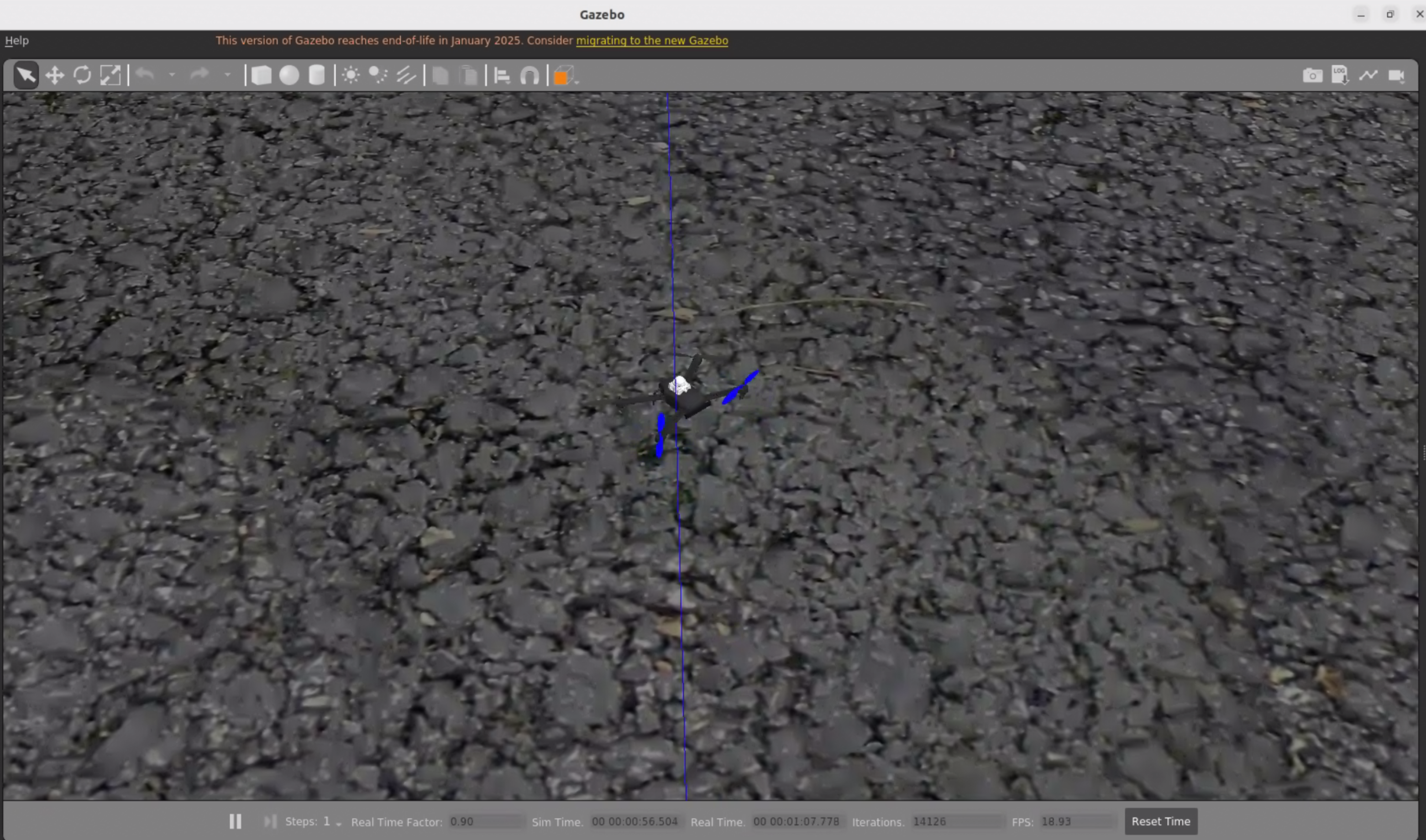
将 AHT 调试好的策略分别送入 DiffAero(训练所用仿真器)、IsaacLab和高保真仿真器 Gazebo 中进行验证。由图可见,策略表现良好,可以说明 AHT 的参数调优并非毫无章法地胡乱调试,而是针对所调试的任务进行深入理解之后进行的调试决策。

下一步
赛后,我们将会继续维护、完善AHT,持续致力于将AHT打造成能够助力更多人科研的调参伙伴,包括但不限于:
支持 Codex、Claude Code 和 Cursor;
支持一轮调试提出多个提案,异步并行执行调试;
支持自动检测 workstation 的GPU数量,自动规划提案数量,根据工作状态分配任务,实现负载均衡与调参效率最大化;
融合 Hydra Optuna 插件,让 agent 自行决定何时要在较小参数空间中使用贝叶斯算法搜索最优值;
......
愿景
AHT 的目标不仅仅是一个调参工具。当编码、调试、头脑风暴和论文撰写都在被 AI 逐步接管时,超参数调优是研究自动化链条上缺失的关键一环。AHT 补上了这一环,让研究者可以把更多时间花在真正需要人类创造力的地方——提出新问题、设计新方法、理解新现象——而把重复性的实验迭代交给 agent。
你只需要告诉 agent 优化什么。剩下的——读代码、定策略、跑实验、总结经验——它都能自己搞定。你喝咖啡就好。☕